阿里Qwen3大模型震撼登场:AI技术再攀新高峰!
2025-05-15
1
在全球大模型技术竞争白热化的背景下,阿里云智能旗下的通义千问团队正式发布了其最新一代开源大模型——Qwen3。凭借其突破性的技术架构与开源生态策略,成为国内为数不多的在多维度性能指标上对标DeepSeek的选手。面对开源大模型固化如深潭的现状,这股新力量的涌入,既搅动了死水微澜,也让水面下的暗流愈发难以预测。
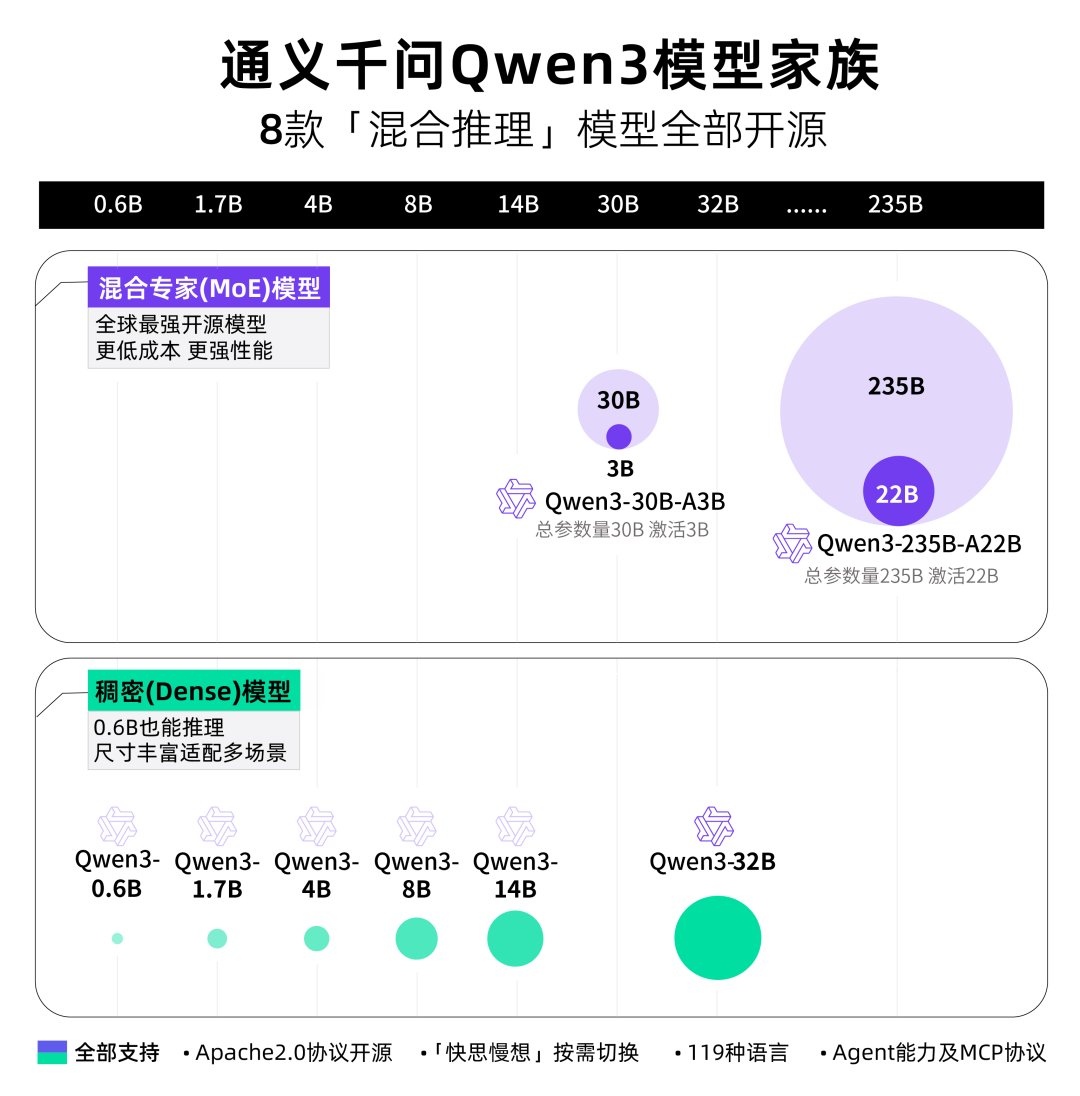
此次开源包括两款MoE模型:
Qwen3-235B-A22B(2350多亿总参数、220多亿激活参)
Qwen3-30B-A3B(300亿总参数、30亿激活参数)
以及六个Dense模型:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B。
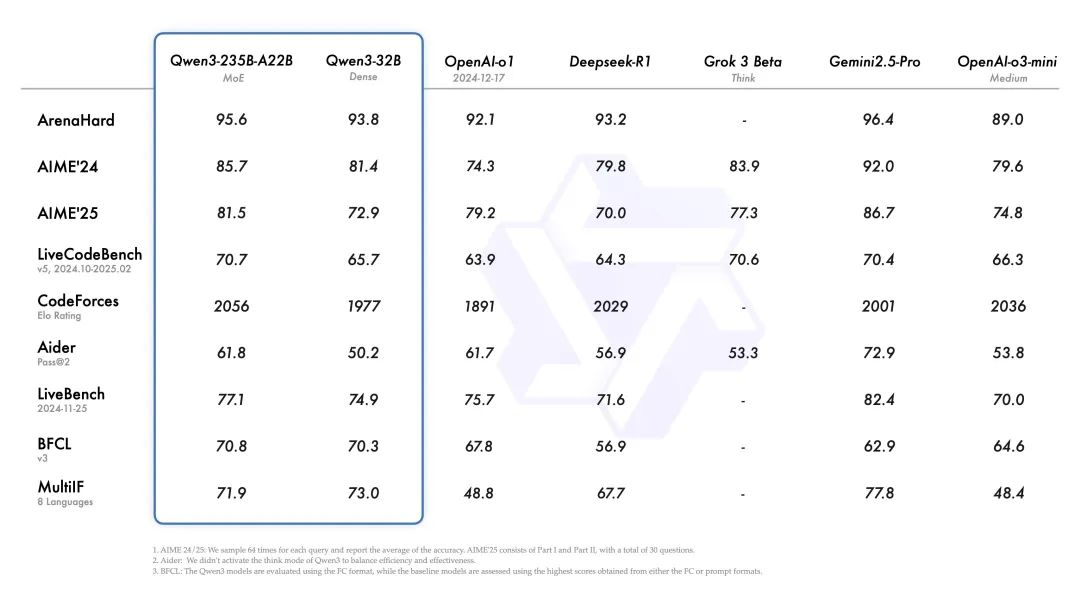
旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,与一众顶级模型相比,表现出极具竞争力的结果。
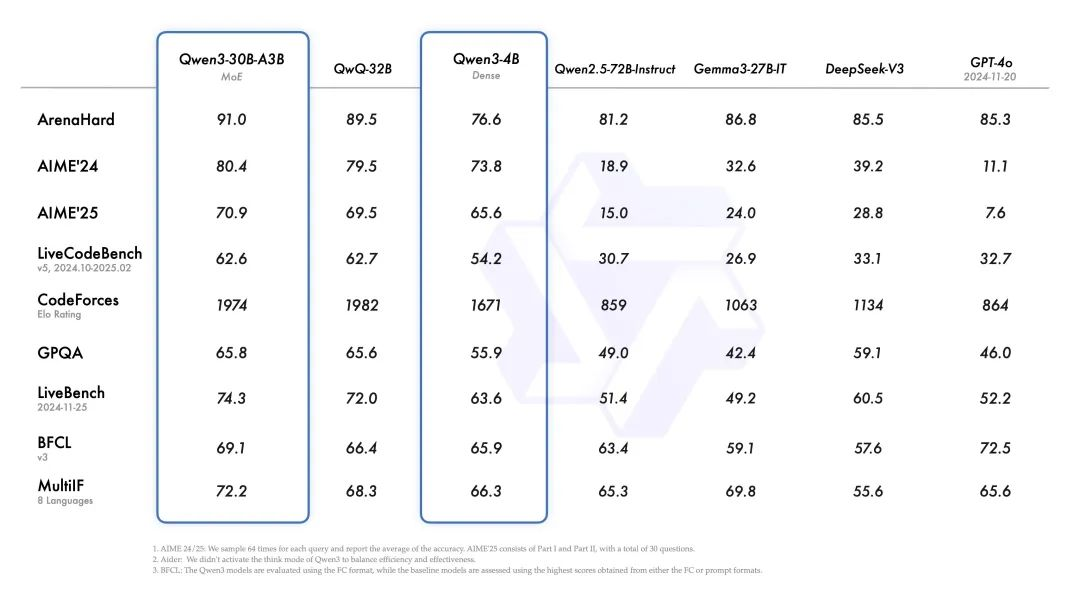
小型MoE模型Qwen3-30B-A3B的激活参数数量是QwQ-32B的10%,表现更胜一筹,Qwen3-4B这样的小模型也能匹敌Qwen2.5-72B-Instruct的性能。
除了在各项基准测试中展现出的优异性能潜力,Qwen3作为新一代开源模型,可能还具备一些值得关注的核心亮点,这些亮点或许能使其在开源社区中脱颖而出:
1.多尺寸模型族:为了满足不同应用场景和硬件条件的需求,高性能大模型通常会发布不同参数规模的版本。Qwen3很可能提供了一系列模型尺寸,从轻量级版本到超大模型,以便开发者和企业可以根据自身资源和应用需求灵活选择。这种“家族式”的发布策略,有助于模型的普及和应用。
2.对中文及多语言的优化支持:作为由中国团队开发的大模型,Qwen3在中文处理能力上可能具备天然的优势,对中文的理解、生成和文化适应性有望达到较高水平。同时,考虑到全球化的AI应用需求,Qwen3也很可能在多语言支持方面进行了重点优化,力求在主流语种上都展现出良好的性能。
3.潜在的推理效率提升:模型的实际应用除了性能,推理速度和资源消耗也是关键因素。Qwen3在架构设计和优化上,可能考虑到了提高推理效率,降低部署成本,使其更易于在实际生产环境中落地。
4.社区友好与易用性:作为一个开源项目,Qwen3的成功很大程度上取决于社区的接受度和参与度。阿里团队可能会在文档、工具链、模型接口等方面下功夫,使其更易于开发者上手和使用,从而快速构建起活跃的社区生态。
这些核心亮点,结合其在性能上的突破,共同构成了Qwen3在开源模型市场中的竞争优势。它们不仅体现了模型的技术实力,也展现了其在实用性和生态构建方面的考量。
一个高性能大模型的诞生,往往是预训练和后训练(包括指令微调、对齐等)两个阶段共同作用的结果。Qwen3之所以能展现出“叫板”DeepSeek的潜力,其核心玄机很可能藏在这两个关键环节的创新与优化中。
1.预训练阶段:海量数据的“精炼”与模型架构的“巧思”
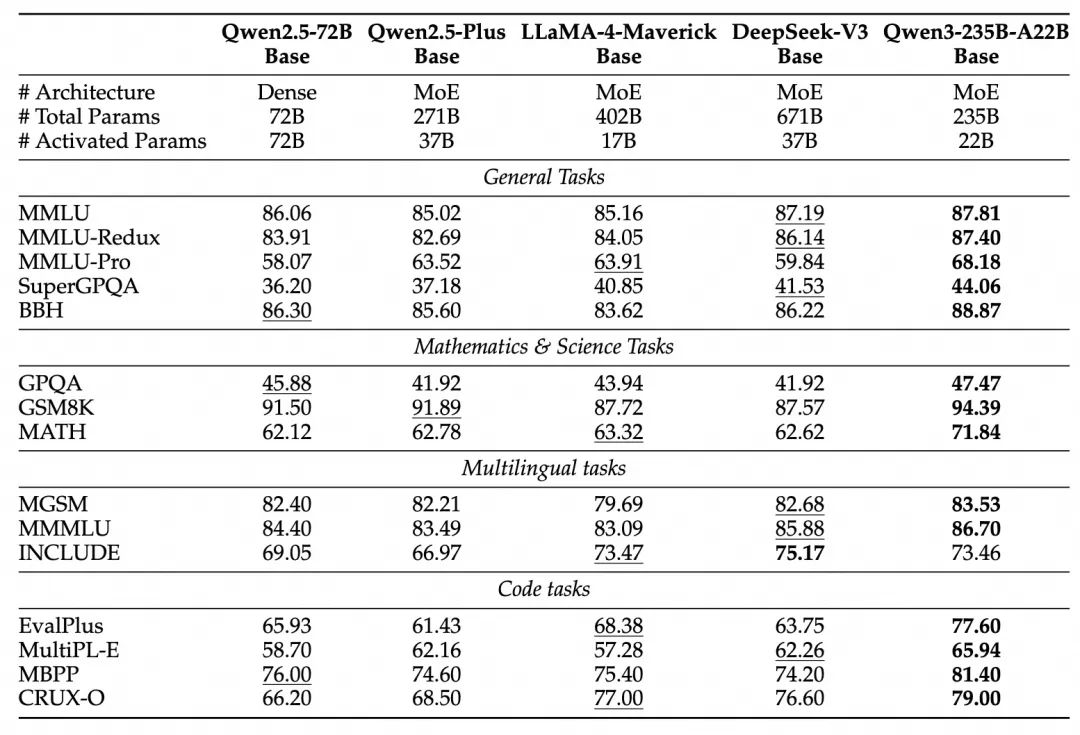
Qwen3的预训练数据量是Qwen2.5的两倍。Qwen3强大的性能很可能首先受益于其庞大且高质量的预训练数据集。这不仅仅是数据的“量”,更在于“质”以及数据的多样性和均衡性。一个全面且去除了大量低质量信息的语料库,能够让模型学习到更纯净、更丰富的世界知识和语言规律。Qwen3可能在构建预训练语料时,投入了巨大的精力进行数据的清洗、去重、过滤,并可能涵盖了更广泛的领域,例如科学、技术、人文、艺术等,以提升模型的通用泛化能力。
模型架构设计同样关键。虽然多数大模型采用Transformer架构,但在层数、隐藏层大小、注意力机制和位置编码等细节上各有不同。Qwen3可能在Transformer基础上进行了优化,比如改进并行计算、内存管理或添加任务增强模块,从而提升训练效率和性能上限。此外,预训练中的优化器选择、学习率调度和分布式训练等技术细节也影响模型效果,Qwen3团队在这些方面可能积累了独特经验。
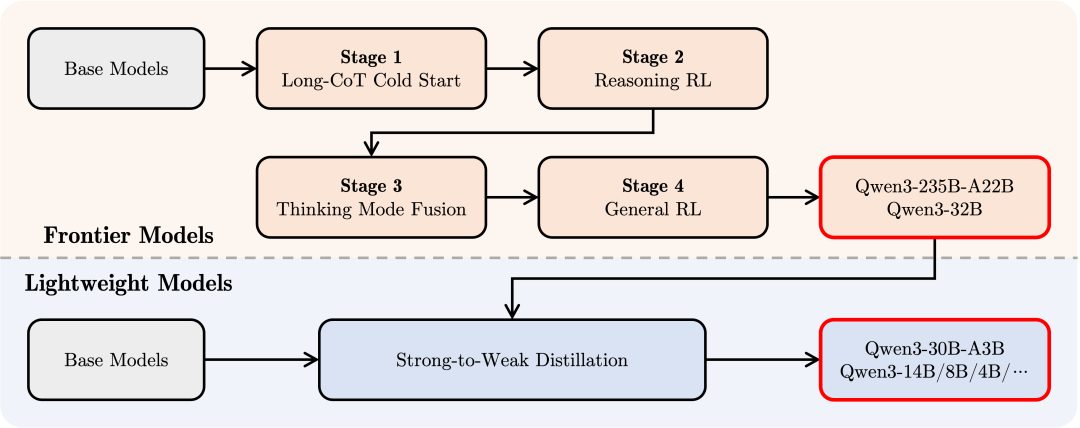
如果说预训练是学习“知识”,那么后训练,特别是指令微调和对齐,就是学习如何“运用知识”以及如何“像人一样”进行交互。许多基础能力不错的模型,在没有经过良好的后训练时,可能无法很好地理解用户意图,甚至会产生有害或偏见性的回复。
Qwen3之所以能在遵循指令、生成有用且无害内容方面表现出色,很可能得益于其精细化的后训练流程:
1)长思维链冷启动,使用多样的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和STEM问题等多种任务和领域。这一过程旨在为模型配备基本的推理能力
2)长思维链强化学习,大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
3)思维模式融合,思维模式融合,通过结合长CoT数据和常用的指令微调数据集对其进行训练微调,这些数据来源于第二阶段的增强思考模型,这一步让模型的推理和快速响应能力无缝融合。
4)通用强化学习,在包括指令遵循、格式遵循和Agent能力等在内的20多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
Qwen3采用改进型混合专家(MoE)架构,通过动态路由算法实现参数高效利用,其最大版本参数量达720亿,支持128k tokens长上下文处理。相较于前代产品,模型引入三大创新:
1.多模态统一框架:融合文本、图像、音频、视频的跨模态对齐能力,支持端到端多任务学习;
2.自适应训练机制:采用动态数据调度策略,在预训练阶段实现知识密度与泛化能力的平衡;
3.量子化推理引擎:通过8-bit低精度计算实现推理速度提升40%,显存占用减少60%。
目前对Qwen3的了解主要基于官方信息和初步评测,其真实实力还需更多社区测评和实际应用验证。我们将持续关注Qwen3的表现,包括:
1.多维度性能对比:与DeepSeek、Llama等主流模型在权威评测中的表现对比。
2.核心能力专项测试:重点评估代码、逻辑推理、长文本处理等核心能力。
3.应用场景适配性分析:考察在问答、创作、编程辅助、智能客服等场景的适用性。
4.技术探讨:基于公开信息分析其模型架构和训练方法。
随着Qwen3在阿里云智能计算平台的大规模部署,中国AI产业正从"模型竞赛"转向"价值创造"的新阶段。这场技术突围不仅关乎算法突破,更预示着云计算厂商在下一代AI基础设施中的核心卡位战。我们期待通过更全面的测试来评估Qwen3的实际能力。